
Continuous Learning: Next Wave in Training and Inference
Every wave of innovation has limitations
Every wave of innovation starts in a similar way: a breakthrough, a gold rush, and then a long (often problematic) line of engineering effort to turn it into real-world potential. The Transformer, introduced in Google’s Attention Is All You Need paper, is one such wave. It unlocked the ability for deep contextual understanding in language models in both training (storing information) and inference (retrieving information). And yet, it has not been fast or easy to turn this Generative Artificial Intelligence into something more than just a chat app. It’s been eight years now, and the field is grappling with band-aids that try to push Large Language Models (LLMs) beyond OpenAI’s ChatGPT and into Agentic AI.
The market knows this. Enterprises are deploying thousands of so-called “AI agents,” yet most are frozen snapshots of yesterday’s data and yesterday’s ability. They can summarize, search, and reason within the boundaries of their static training, but they cannot truly learn. They cannot internalize new information/experiences or update themselves continuously. For entrepreneurs, this is the central bottleneck. For investors, this is the opportunity.
So ask yourself: Are you using any of the following techniques to augment LLMs (i.e. AI Agents)?
Fine-Tuning: The process of retraining a pre-trained large language model on a smaller, domain-specific dataset to improve its performance on specialized tasks. It requires collecting labeled data, running new training cycles, and redeploying the updated model.
Prompt Engineering: The craft of designing and optimizing input instructions (prompts) to guide a language model’s behavior and improve output quality, often compensating for the model’s lack of native understanding or control.
Large Context Windows: Expanding the amount of text or tokens a model can “see” at once during inference to improve reasoning and recall. While it can improve context awareness, it’s computationally expensive and increases hallucinations.
Retrieval-Augmented Generation: A technique that supplements a language model’s responses with information retrieved from external knowledge sources (like databases) at query time, allowing it to access newer or more specialized data without retraining.
Now ask yourself: Do you (or organization) have the technical skills to implement the above? And event if you have the skills to implement such techniques or band-aids, the landscape of AI agents is plagued by failure modes. Agents are frequently tripped up by multi-step tasks, mishandled confidential information, and brittle generalization across domains.
A recent study, led by Salesforce AI researchers, found that agents succeed only ~58% of the time on simple, one-step tasks, and the rate falls to ~35% with multiple-step tasks. Even worse, agents often lack an internal understanding of sensitivity or privacy concepts. They struggle to discern when data should remain confidential, and prompt-based patches degrade quickly over extended interactions, even when fine-tuning techniques are applied. At scale, enterprise deployments of agents encounter thorny problems such as coordination across modules, consistency across contexts, and maintaining knowledge coherence. In practice, implementations often revert to brittle prompt logic or external retrieval tricks rather than real understanding. What is needed is a system in which agents can internalize learning continuously, safely, and contextually, so they can absorb new facts, preserve prior knowledge, reason over multi-step interactions, and scale in changing environments without fragile prompt patches.
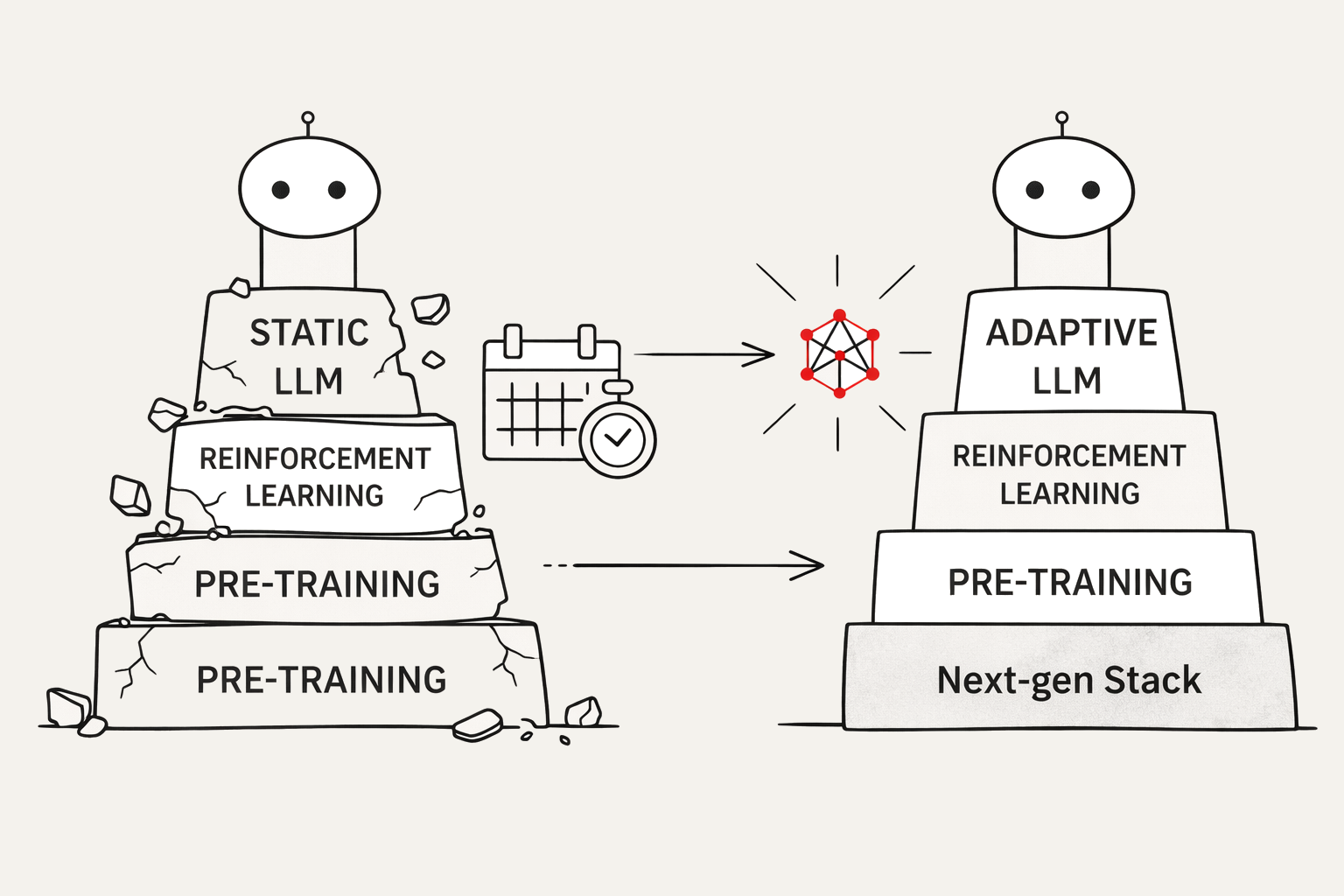
Each technique patched with Band-Aids
Despite large investment in generative AI, most attempts to extend model capabilities rely on stopgap measures. Instead of addressing the core limitations of static learning, the field has layered patch after patch onto frozen foundations. The result is a series of techniques that offer temporary relief but fail to create truly adaptive intelligence.
Pre-training. Every large model begins as a massive snapshot of the world, frozen at a point in time. It “knows” billions of facts but cannot integrate new ones. These base models are built by a handful of frontier providers. Everyone else can only fine-tune on top of them, and still an expensive process that fails to produce activate adaptation.
Fine-tuning. The standard fix for augmenting static models has been supervised fine-tuning. It’s slow, costly, and brittle. You collect new examples, retrain for hours, days or even weeks, and risk losing what the model already knew. It’s more a stylistic imprint than a conceptual upgrade. Agents trained this way do not evolve; they are re-skinned versions of a frontier model.
Reinforcement Learning. RL for short, added the promise of improvement through feedback, but at scale it depends on handcrafted reward signals, repeated runs, and massive compute budgets. Fine-tuning with RL may improve helpfulness or style, but it remains fundamentally batch learning. The feedback loop is slow (hours, days or weeks) for any agent meant to adapt live.
Prompt Engineering. To workaround these training limitations, the industry often shifts the burden to a collection of statement contexts. Agents are guided by increasingly elaborate prompts that try to simulate intelligence through instruction. It works superficially, but it’s a mirage that barely holds. The agent itself remains static. Each session starts fresh; nothing is truly learned.
Large Context Windows. Then came larger and larger memory buffers, so the model could “see” more text at once. But this only delays the problem. A model without internal learning can read a long history but forget it the moment the window resets. However, even worse is that as the window grows, the error curve steepens, increasing hallucinations rather than reducing them.
Retrieval-Augmented Generation (RAG). Finally, retrieval systems bolted external data onto internal models. They made AI appear smarter by feeding it context in real time. But the knowledge lives outside the model, in embedding databases that drift and decay. Nothing is internalized. Nothing grows. RAG is a prosthetic memory, not a mind. Time has shown this is not the path forward.
Each of these techniques adds time, cost, and complexity. Together, they form the current software stack for AI Agent workloads — a tower of blocks band-aided together, struggling to hold up an agentic architecture. And yet, the next leap forward will not come from adding another block or another band-aid. It will come from rethinking the stack itself — building systems that learn continuously. True progress will come from a tech stack that treat learning as a perpetual process, not a one-time event locked behind retraining cycles.
Next-Generation Agentic AI Tech Stack
The market does not need yet another fine-tuning framework, another block in the stack, or another academic paper on how to tweak the latent space of LLMs. It needs a foundation that breaks the cycle of retraining and makes true adaptive intelligence possible. The core limitations that hold both LLMs and agents back must be addressed directly.
Continuous Reinforcement
Agents today can act but they cannot truly adapt. They observe feedback but cannot integrate it without slow, external orchestration. What is needed is a way for models to learn as they operate, turning live interaction into ongoing improvement. Instead of repeatedly updating weights offline or invoking retraining pipeline, the agent itself should evolve from experience, closing the loop between perception, reasoning, and adaptation in real-time.
Single-Pass Learning Efficiency
The economics of agent training collapse under traditional fine-tuning methods. Each behavioral correction requires large datasets, multiple training cycles, and massive compute. A more sustainable approach would allow every experience to be consumed once, its insight absorbed immediately, and the lesson integrated into the model’s weights. Agents could then update continuously at the edge without reliance on expensive retraining infrastructure.
Overfitting and Forgetting Protection
Agents operating in live environments cannot afford to lose prior skills each time they learn something new. Adaptation must be bounded, reversible, and safe, ensuring that new concepts and lessons do not erase what came before. The result would be agents that remain stable and reliable even while learning on the job, where memorization versus generalization is not only understood but strategically leveraged.
Integrated and Persistent Knowledge
Knowledge should not be bolted on through prompts or retrieval systems. Instead, it should be absorbed directly into the model’s semantic space through its own runtime experience. Agents should become genuinely more capable through direct interaction rather than depending on external memory stores to appear intelligent. Every learned update should be logged, versioned, and rolled forward safely, enabling long-term skill accumulation without the cost or complexity of repeated retraining. The agent’s memory should become durable and contextual, transforming short-term reactions into long-term capability.
Live, Autonomous Intelligent Agents
With incrementally active learning, agents could reduce hallucinations, retain past knowledge, and become more capable with every interaction. They would stop replaying static behavior and begin demonstrating measurable progress. Each conversation, task, and feedback loop would become a moment of growth.
For investors and entrepreneurs, this is not about marginal optimization. It is about the next platform shift: moving AI from static pattern reproduction to adaptive cognition. It is the bridge between today’s brittle, prompt-bound agents and a generation of autonomous systems that evolve, specialize, and improve safely in the field. The winners of the next AI era will not be those who build larger models, but those who build models that grow smarter with every interaction.
The AI Stack for the Next Era of Agents
At LatentSpin, we are reimagining how agents learn. Our foundation is Conceptual Adaptation Theory (CAT → ULTU), mathematical methods to unify the way models acquire and evolve knowledge. It replaces brittle, costly, and complex training methods with mathematically controlled reinforcement learning that enables continuous, single-pass (think one-shot) adaptation. Rather than retraining on massive datasets to combat overfitting or catastrophic forgetting, AI Agents built on this approach learns from each experience once, updating its weights proportionally while remaining stable. The result is a shift from static and fragile LLMs to adaptive and self-improving systems. Leveraging such methods, LatentSpin is developing a platform that automates the training, deployment, and execution of AI agents, enabling knowledge workers to create, manage, and run agents that grow smarter on their behalf.