
Real-Time, Single-Pass: The Next Frontier in Adaptive Intelligence
Limitations of Today’s AI
In a previous post (Real-Time Learning: The Leap LLMs Must Take), I outlined the leap that AI systems must take, from static models to real-time learners. I argued that the current paradigm of Fine-Tuning and related patchwork of Prompt-Engineering and/or Retrieval-Augmented-Generation (RAG) is reaching its practical and conceptual limits. Today’s frontier Large Language Models (LLMs) may appear intelligent, but at their core, their learnings are frozen. They respond well, but they do not adapt. They simulate, even embody, reasoning, but they do not restructure how they think in response to new experiences.
At LatentSpin (https://www.latentspin.ai), our work has focused on addressing this gap, developing agentic systems that not only generate language and associated actions, but also learn and evolve in the moment. This led to the development of Conceptual Adaptation Theory (CAT), a lightweight, mathematically grounded control mechanism that enables models to adapt their internal structure in real-time. But as we’ve continued to explore and test such a new architecture, a deeper opportunity emerged, one that reframes what learning actually looks like in intelligent systems. We call it Real-Time (RT)Single-Pass (SP) learning.
Single-Pass Learning Matters
Traditional training assumes that learning requires multiple exposures: datasets are shown again and again, parameters are nudged repeatedly toward convergence, and training loops are measured in thousands of steps. But this isn’t how humans often learn. In real life, a single surprising moment, a confident mistake, or a contradiction to prior knowledge can permanently reshape our understanding. Real-time single-pass learning in humans is efficient, selective, and experience-driven. The question we asked was simple: can machines do the same?
As we build out the architecture, the answer appears to be yes. We’ve implemented a learning loop where a model’s reasoning behavior can be modified (gently + safely) after a single exposure to a novel input. The loop evaluates how wrong the model was at prediction error (ε), how confident it was (π), and what kind of structural change it would undergo (ΔS). If the model is confidently wrong (often the most valuable signal) it is allowed to update a small number of internal parameters, typically through mid-layer adapters like LoRA, within a carefully monitored trust region. This ensures that changes are meaningful but never destabilizing.
What makes this fundamentally different from traditional approaches is that this process is not open-ended or iterative. Each update is governed by an internal control loop that evaluates structural change, prediction error, and confidence in real time. Learning is not repeated until convergence, but instead triggered and terminated based on the model’s internal state. In this sense, single-pass learning is not just about efficiency, it is about replacing iteration-driven learning with state-driven learning.
Precision Without Overfitting
What makes this compelling isn’t just the speed, it’s the precision, without overfitting or catastrophic forgetfulness. Instead of averaging over hundreds of examples, CAT controls lets a model learn from the one that matters. And instead of retraining over days or weeks, the model adapts in milliseconds. Each exposure becomes a diagnostic probe: not part of a batch, but a challenge to its internal logic. If it handles the new knowledge correctly, it moves on. If it fails, and fails confidently, it learns.
We are running experiments where this kind of single-pass adaptation produces real, measurable benefits. A model exposed to a novel fact or task improves its reasoning on that content immediately, without harming its performance on prior benchmarks. Because such control keeps a reference model through exponential moving average it can roll back “bad” updates automatically. And because every adaptation is logged: ΔS, ε, π, and Kullback–Leibler divergence, such control offers a rare degree of transparency in how the model evolves over time. This isn’t just an optimization trick. It’s a new way to think about how intelligence grows.
Real-Time Single-Pass with CAT control equations breaks down the rigid boundary between training and inference. It challenges the assumption that reasoning must be frozen at runtime. In traditional AI systems, inference is seen as a read-only process: the model responds, but it does not reflect. With CAT, inference becomes a two-way street. Every interaction is both response and opportunity. Every reasoning step is also a moment of potential improvement.
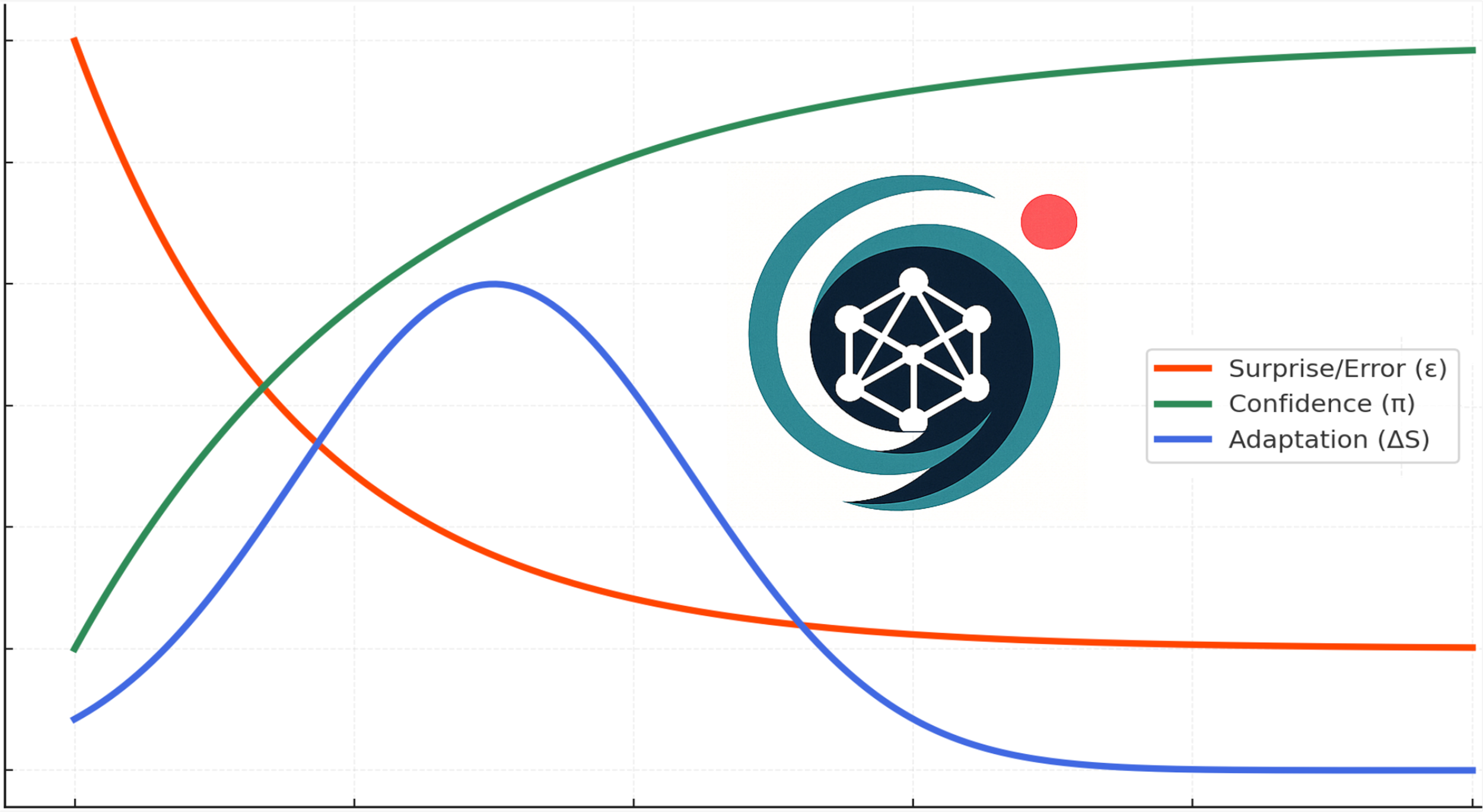
And this is where such controls also shed new light on the classic tension between memorization and generalization. By tying the size of structural updates (ΔS) to the interplay of surprise and confidence (ε·π), CAT gives models a lawful way to decide when to store detail and when to reorganize an actual concept. Small ΔS at low ε·π looks like memorization, absorbing facts without the issue destabilizing prior knowledge. Larger ΔS at high ε·π looks like generalization, rewiring abstractions to make sense of the unfamiliar. Push ΔS too far relative to ε·π and one gets brittle overfitting; push it farther still and priors collapse into catastrophic forgetting. Seen through this lens, even double descent starts to make sense: small models are trapped in shallow memorization, mid-sized models mis-scale updates and overfit, but large models distribute ΔS across many degrees of freedom, unlocking smoother structural rewires and stronger generalization. CAT equations turn these phenomena from curiosities of training curves into a controlled spectrum of learning behaviors.
Safety as a First Principle
Critically, we’ve designed systems to be safe, interpretable, and deployable. Learning is constrained to modular surfaces (i.e., adapters), rollback is built-in, and performance anchors are used to validate that adaptations help rather than harm. When the model adapts, it’s not guessing, it’s doing so with precision and accountability. And when it makes a mistake, it doesn’t need to wait for a retraining cycle. It can fix (i.e., evolve) its logic, selectively and immediately.
We see this as foundational for building the next generation of AI agents. Autonomous systems can’t afford to make the same mistake repeatedly. They must learn from each encounter. But that learning systems must also be resilient, robust to noise, anchored in confidence, and traceable. With that said, in the coming weeks, we’ll begin sharing our experiments and initial agent workflows. Our goal is to demonstrate that real-time reasoning adaptation isn’t just theoretical, it’s real, measurable, and ready to be tested by others.
The natural extension of this work is a future where agentic services are not just automated, but truly autonomous. Imagine long running digital agents that continually refine their reasoning with every customer interaction, every security alert, or every sensor reading, without requiring engineers to constantly retrain or redeploy them. These self-learning agents could personalize support, detect emerging threats, or optimize complex workflows in real time, not by cycling through static models but by evolving their logic in the moment. Just as the web transformed how we access information, autonomous self-learning agents may transform how we build, deliver, and experience services. They would not merely execute instructions but grow alongside the environments they inhabit, becoming partners in adaptation.
Toward General Intelligence
Looking ahead, we believe this approach has implications far beyond agentic solutions. Whether it’s in control systems, robotics, or future AGI systems, the ability to adapt reasoning in a single pass (without offline retraining, overfitting or forgetting) may prove to be the defining feature of artificial intelligence that ultimately learns like we do.
We’re just getting started.