
Knowledge is for models, Execution is for context
AI has a language problem. As agents become more capable, the industry is starting to use several powerful terms interchangeably: recursive self-improving, continuous learning, and continual learning. Each term sounds like progress. Each suggests that an AI system gets better over time. But in practice, these phrases are now being applied to very different mechanisms. Some systems improve by changing code. Some improve by saving memories. Some improve by retrieving better context. Some improve by updating prompts, tools, policies, or workflows. A much smaller set actually changes the model itself.
That distinction matters because the value is not the same. A system that retrieves more context is not the same as a model that has learned. A system that stores a memory is not the same as a model that has internalized knowledge. A system that updates an agent workflow is not the same as a deployed model that improves its own capability from validated experience. These are all useful forms of adaptation, but calling all of them “learning” muddies the most important question: where does the improvement live?
This is especially visible in the phrase “recursive self-improvement.” In many cases, what people mean is that AI assists in the process of improving AI systems. It can write code, run experiments, suggest architectures, optimize prompts, create evaluations, or automate parts of the research loop. That is valuable. It may dramatically accelerate development. But the deployed model is often not learning in the moment. The improvement happens around the model through engineering, experimentation, validation, and release cycles. That is not wrong, but it is not the same thing as the model itself continuously learning from experience.
The same muddying is happening with “continuous learning” and “continual learning.” Some companies use these terms to describe memory systems that save user preferences, facts, summaries, or prior interactions to disk and retrieve them later. Others use them to describe context management, where the system decides what information to bring into the prompt and what to leave out. Others use them to describe agent improvement loops, where failures become test cases and the system updates prompts, tools, policies, or routing decisions. Again, these can all be useful. But they are not the same as in-model learning.
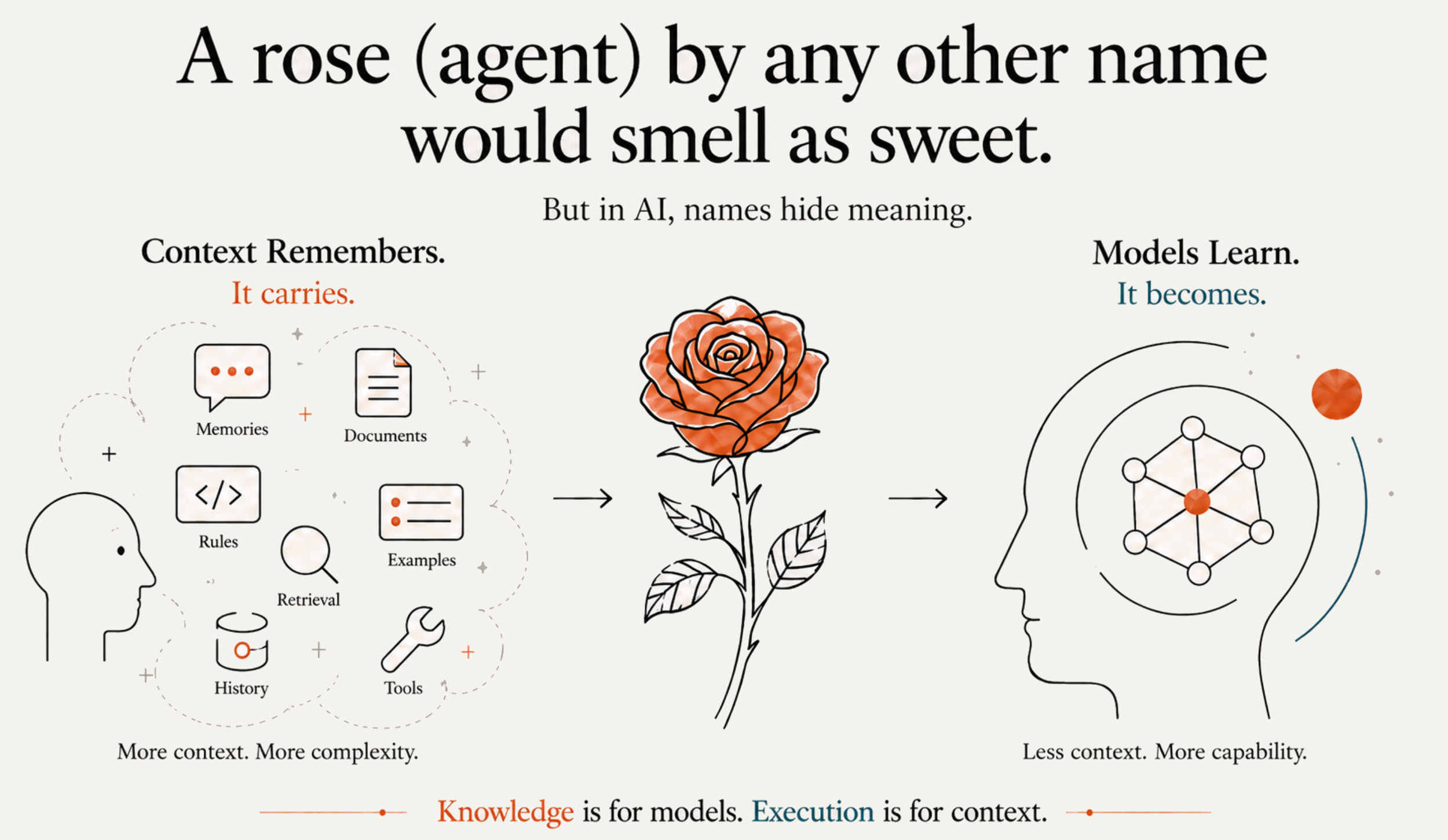
The clean distinction is this: memory adds context, learning changes capability. If an improvement disappears when the context disappears, then the model did not learn. It was reminded. It was given better notes. It was surrounded by a better scaffold. But the knowledge was not internalized. A true learning system should pass what we can call the No-Context Test. Teach the system something, remove the retrieved memory, examples, prior conversation, prompt patch, and external context, then test again. If the improvement remains, the learning is in the model. If the improvement disappears, it was context management.
This distinction is not academic. It directly affects accuracy, performance, cost, and simplicity. When companies simulate learning by adding more context, they often create what we call a context riot. The prompt becomes a crowded room filled with memories, rules, examples, tool outputs, policy fragments, retrieved documents, summaries, corrections, and workflow instructions. The model is asked to sort through all of it every time. This can help, but it is fragile. Context can be incomplete, stale, contradictory, irrelevant, or too large. The more the system depends on context to behave correctly, the more opportunities there are for confusion and hallucination.
In-model learning changes the economics. When validated knowledge is learned into the model, accuracy improves because the system does not have to reconstruct the right answer from a noisy pile of retrieved context. The model becomes more capable. It develops domain-specific understanding, behavioral corrections, and repeated patterns as part of its internal capability. That does not eliminate the need for context, but it puts context back in its proper role. Context should carry the live task, not every lesson the model failed to learn.
Performance improves for the same reason. Context-heavy systems spend tokens explaining things the model should already know. They retrieve, rank, summarize, inject, and reason over supporting material before they can act. Every extra token adds latency. Every retrieval step adds overhead. Every orchestration layer adds complexity. If a smaller model has learned the specific knowledge and behavior it needs, it can respond with fewer tokens, fewer retrieval calls, and less scaffolding. The system becomes faster because it is not carrying its entire education into every task.
Cost improves because in-model learning allows smaller open-weight models to become more specialized and capable over time. Today, many teams rely on large frontier models because those models are broad enough to compensate for missing domain knowledge. But this is expensive, and it often forces companies into a pattern of using large models plus large context windows plus heavy retrieval. In-model continual learning creates a different path. A smaller model can learn the specific environment, tasks, corrections, and domain patterns that matter. The result is not just cheaper inference. It is a more efficient model of intelligence, where capability accumulates instead of being repeatedly rented through tokens.
Simplicity may be the most underappreciated benefit. Traditional training pipelines are backend-heavy and operationally difficult. They require dataset creation, labeling, formatting, fine-tuning, evaluation, deployment, monitoring, and rollback. Prompt and memory systems are easier to start with, but they become complex over time as rules, memories, retrieval policies, and workflows accumulate. LatentSpin’s view is different. Teaching should happen in natural language. A user should be able to correct, guide, demonstrate, and validate behavior, while the system automates the path from instruction to learning. The goal is not to make every user a machine learning engineer. The goal is to let the model learn from the way people naturally teach.
This leads to a better architectural principle: knowledge is for models, execution is for context. Context is not bad. Context is essential. It carries the live task, the current user intent, tool outputs, documents, constraints, and temporary state. But context should not become the permanent dumping ground for everything the model failed to learn. Durable knowledge belongs in the model. Execution-specific information belongs in context. When these roles are confused, systems get heavier. When these roles are separated, systems get simpler.
The boundary between knowledge and execution is dynamic. A new instruction may belong in context because it is temporary, unproven, or task-specific. A rare edge case may remain in context because it is not worth internalizing. But when an execution pattern becomes common, validated, and valuable, it should become knowledge. It should move from context into the model. That is how agents develop instinct. At first, the system needs instructions. Then it needs reminders. Then it sees the same pattern enough times, with enough validation, that the behavior should become internalized. The model should not need to be told forever.
This is the LatentSpin loop: Execute, Validate, Internalize, Simplify. The agent executes the live task using context. The system validates what worked, what failed, what repeated, and what mattered. LatentSpin internalizes the validated pattern into the model. Future execution becomes simpler because the system needs less context, fewer tokens, fewer prompt patches, fewer retrieval calls, and less orchestration. Memory-based agents get heavier over time. In-model learning agents get lighter.
This is why “in-model” matters. It is not just a branding phrase. It names the mechanism that context systems cannot claim. Context can remind a model. It cannot make the model know. Retrieval can supply information. It cannot turn that information into durable model capability. Prompt patches can steer behavior. They do not create learned instinct. In-model continual learning is different because the model itself updates from validated experience.
LatentSpin’s definition is simple: In-Model Continual Learning is the process of converting validated experience into durable model capability, so agents become more accurate, faster, cheaper, and simpler over time. Knowledge is for models. Execution is for context. When execution becomes common, validated, and valuable, LatentSpin turns it into in-model knowledge: persistent learned instinct.